
I am a quantitative researcher at Two Sigma.
I got my Ph.D. from the Department of Statistics & Data Science at Carnegie Mellon University in May 2018, under supervision of Professor Kathryn Roeder and Professor Jing Lei. My research spanned a wide range of topics, including network community detection, high-dimensional inference, hierarchical modeling, unsupervised clustering, as well as many exciting applications in genetics. Some of the codes for my research are available on GitHub.
I also hold a M.S. in Machine Learning from Carnegie Mellon University. Before coming to CMU, I got my B.S. in Statistics and secondary B.A. in Economics from Peking University, China, in 2013.
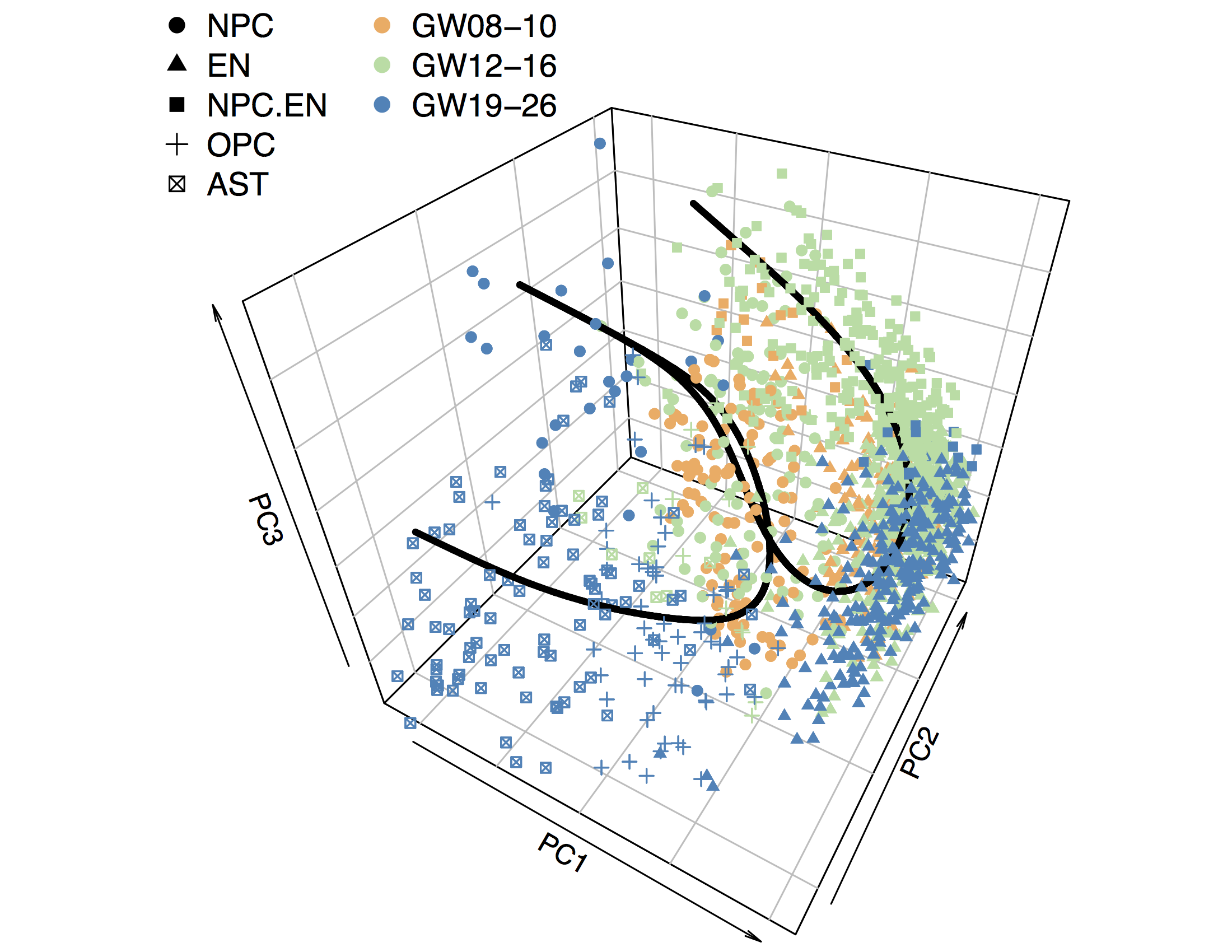
We consider the clustering problem in single cell data with the existence of both (i) pure cells, each belongning to one single cluster, and (ii) mixed cells (transitional cells), that are transitioning between cell types. We propose SOUP, for Semi-sOft clUstering with Pure cells, which performs well at the hard-clustering problem for pure cell types and excels at identifying transitional cells with soft memberships. Notably, SOUP is derived under a generic additive noise model and can be versatile and applicable to a wider range of applications.
Semi-soft clustering of single cell data.
Proceedings of the National Academy of Sciences Jan 2019, 116 (2) 466-471
(manuscript) (preprint) (code)

Recent advances of single cell sequencing yield valuable insights about individual cells. However, compared to traditional tissue-level bulk RNA-seq, analyzing single cell data is challenging because of high levels of technical noise. Here, we proposed a unified statistical framework for joint analysis of single cell and bulk RNA-seq data. Our hierarchical model borrows the strength from both data sources, identifies noisy entries in single cell data, and leads to a more accurate estimation of gene expression profiles.
A unified statistical framework for single cell and bulk RNA sequencing data.
Annals of Applied Statistics, 12(1):609-632.
(manuscript) (preprint) (code)

At Uber, probabilistic time series forecasting is used for robust prediction of number of trips during special events, driver incentive allocation, as well as real-time anomaly detection across millions of metrics. Classical time series models are often hard to tune, scale, and add exogenous variables to. In this project, we proposed a novel end-to-end LSTM-based Bayesian deep model that provides time series prediction along with uncertainty estimation. This model has been successfully applied to large-scale time series anomaly detection at Uber. This work was completed during an internship.
Deep and confident prediction for time series at Uber.
ICDM'17 Workshop.
(manuscript) (preprint) (blog post)
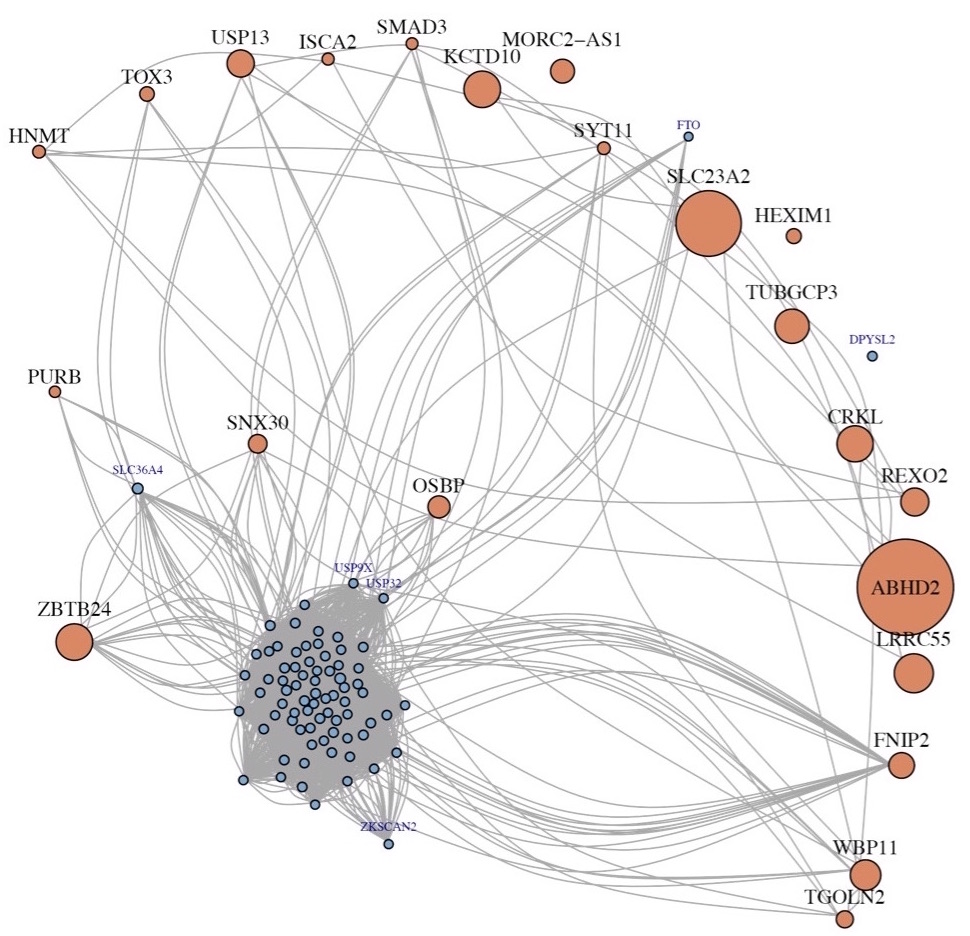
Two-sample test for high-dimensional covariance matrices is a long-lasting and challenging statistical problem. Here, we proposed a novel perspective that utilizes the spectrum of the differential matrix, which is closely related with Sparse Principal Component Analysis. Our test remains powerful even when the signals are sparse and weak, and outperforms existing approaches under various practical scenarios. We successfully applied our method to the largest gene expression dataset comparing schizophrenia and control brains, and revealed intriguing patterns of gene-gene co-expression change.
Testing high-dimensional covariance matrices, with application to detecting schizophrenia risk genes.
Annals of Applied Statistics, 11(3):1810-1831.
(manuscript) (preprint) (code)
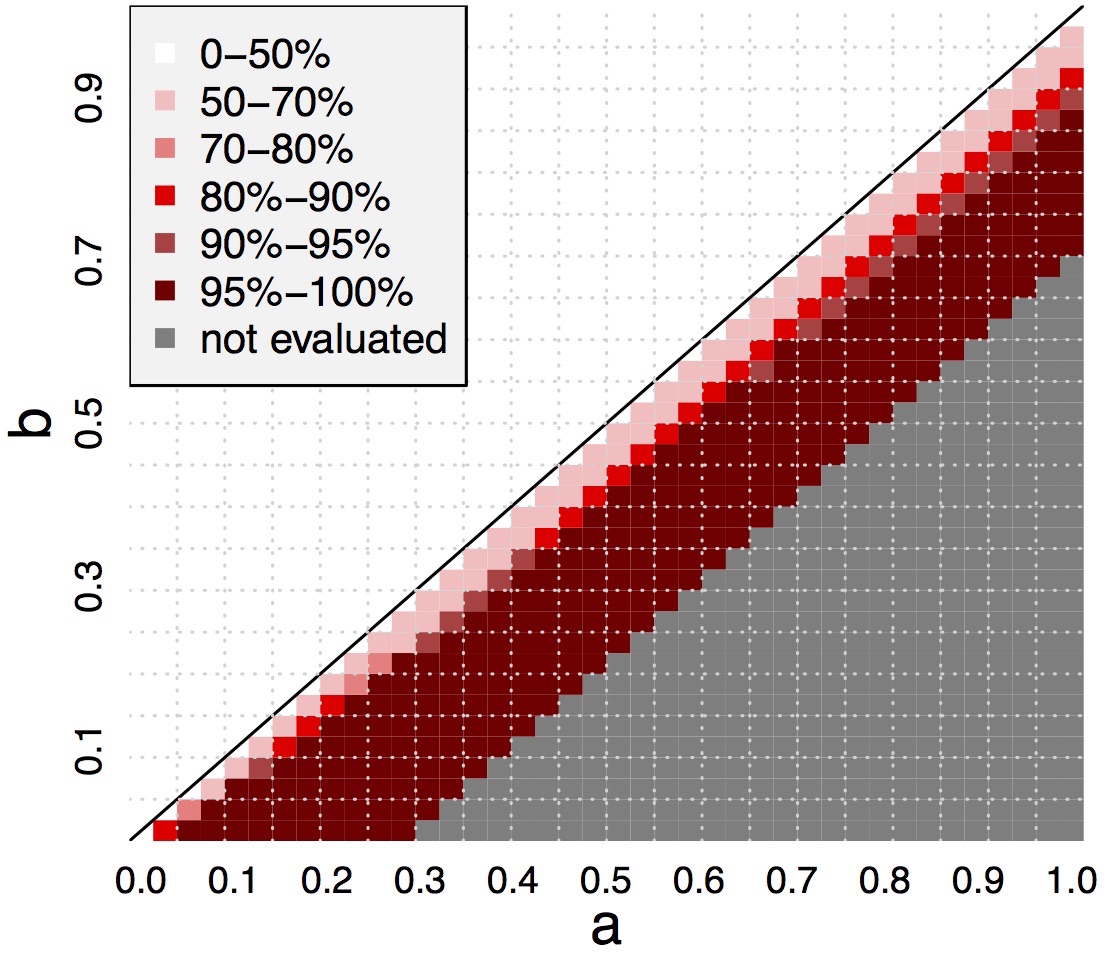
In this project, we study the problem of community recovery in stochastic block models. We show that a simple sample splitting trick can refine almost any approximately correct community recovery method to achieve exactly correct community recovery, when the expected node degrees are of order log(n) or higher. Our results simplify and extend some of the previous work on exact community recovery using sample splitting, and provide better theoretical guarantee for degree corrected stochastic block models.
Molecular Psychiatry.
(manuscript)
Science, 362(6420):eaat6576. (*Equal contributions)
(manuscript) (news)
Nature Genetics, 50(5):727–736. (*Equal contributions)
(manuscript) (news & views)
-
Deep and confident prediction for time series at Uber (talk).
2017 International Conference on Data Mining Workshop (ICDM), New Orleans, LA. -
Estimating uncertainties in neural networks for time series prediction at Uber (poster).
2017 Uber’s Machine Learning Session, San Francisco, CA. (Best presentation award) -
A two-sample test for high-dimensional covariance matrices via sparse principal component analysis (special talk).
2016 Joint Statistical Meetings (JSM), Chicago, IL. (Student paper award) -
Detecting schizophrenia genes via a two-sample test for high-dimensional covariance matrices (invited talk).
2016 ICSA Applied Statistics Symposium, Atlanta, GA. -
On the prediction of risk for autism from common variants (invited talk).
2015 World Congress of Psychiatric Genetics (WCPG), Toronto, Canada. -
On the prediction of risk for autism from common variants (poster).
2015 American Society of Human Genetics Annual Meeting (ASHG), Baltimore, MD.
- Umesh K. Gavasakar Memorial Thesis Award in Statistics, Carnegie Mellon University, May 2018
- 2018 Student of the Year, ASA Pittsburgh Chapter, April 2018
- Student Paper Award, Joint Statistical Meetings ASA Nonparametrics Section, July 2016
- Outstanding Graduate Award, Peking University, July 2013
-
Data Scientist Intern @ Uber, May - Aug 2017
(see my intern project on Uber Engineering Blog and in our ICDM workshop paper) - Decision Analyst Intern @ PNC Financial Services, May - Aug 2015
- Founding member of CMU Statistics department help network, May 2017 -- May 2018
- Program committee of ICDM 2018 Workshop on Data Science and Big Data Analytics
- Reviewer for Journal of the American Statistical Association, Nucleic Acids Research, Statistical Analysis and Data Mining, Biometrical Journal, IEEE Transactions on Neural Networks and Learning Systems, Information Fusion